
Cutting our Lead page LCP by half
At Close, speed is an essential part of our identity. It’s even in our company’s mission: double the sales performance of every small scaling business. In order to deliver that, we must build a CRM that feels modern, reacts snappily, and – most importantly – a CRM that doesn’t get in the way.
Choosing a metric
There are many different ways of measuring performance, and many experts to look to for guidance. Google has always been a proponent of performance and good user experience and they created what they call Core Web Vitals. Web Vitals are composed by three important metrics:
- Largest Contentful Paint (LCP): measures loading performance.
- Interaction to Next Paint (INP): measures interactivity.
- Cumulative Layout Shift (CLS): measures visual stability.
They also created a tool called Lighthouse, which gauges metrics that are important for good user experience. INP can't be measured without a user, so they use Total Blocking Time (TBT), which is a lab metric vital in catching and diagnosing potential interactivity issues that impact INP.
It’s impossible to find one metric that “rules them all”. We could use Lighthouse score (which uses a weighted average of a few different metrics), but we didn’t want to choose a metric prone to formula changes, as we aim to check our progress over time.
So, to set our 2024 goals, we decided to use LCP. We still measure TBT, CLS, and a few other metrics, but LCP seemed like the best catch-all because:
- Both our backend and our frontend have an impact (different from, e.g., TBT which is frontend-only).
- If we improve LCP on one page, we’re most likely improving:
- Loading time (and other metrics like “Visually Complete”).
- Client navigation speed.
- LCP on all other pages.
The next question was which page to focus on. To start, we chose the Lead page, because it's the heart of our app and where our customers spend most of their day.
The Lead page is super packed with a lot of information about the Lead (Addresses, Tasks, Contacts, Opportunities, Custom Objects, Custom Fields) and a feed with all the activities that happened (Meetings, Emails, Phone Calls, SMSs, Notes, etc). So, if we can make the Lead page fast, we’re most likely making other pages fast as well.
Our goal
In the beginning of 2024, the LCP of our Lead page was 7.4s (using a slow machine). Most of our customers would see better numbers than that, but again, if we make it faster for slower machines, we’re most likely making it faster for everyone. We decided to set the following goals:
| LCP on Lead page | Goal (sec) | Goal (%*) |
|---|---|---|
| 2023 EOY | 7.4 | 0 |
| 2024 Q1 | 6.7 | -10% |
| 2024 Q2 | 5.9 | -20% |
| 2024 Q3 | 5.2 | -30% |
| 2024 Q4 (EOY) | 4.5 | -40% |
*_ Percentage change relative to 2023 EOY_
Not a very promising start
The first half of the year did not yield positive results. The reason? Our 2024 product roadmap was too exciting, and our engineering team is too productive!
In Q1, while I was busy
upgrading our router,
the team added
call transcripts, summaries,
@mentions, and comments.
Then in Q2, while I was grinding away implementing
loaders and removing a big
legacy dependency (moment-timezone), the team added
file attachments, the
AI Rewrite assistant,
and
Lead summaries.
At the end of Q1, our LCP had basically made no progress. After Q2, we finished at 8.2s, 11% worse than where we'd started.
Focused work to reduce LCP
Although the work done for performance in Q1 and Q2 was relevant, it was mostly focused on setting us up for success in the future, not really in improving performance a lot upfront.
So in Q3 this had to change, and the main focus was to get closer to our EOY LCP goal.
Planning the cycle
At Close, we work with Shape Up-inspired 6-week cycles and when C5 (Aug 26 – Oct 4) started, we had a few things in mind, but most of the cycle would be dedicated for investigation and exploration.
Knowns
- Time zone list: We were generating time zone names at runtime with the Intl API. This code took ~90ms on a fast machine, and 200ms+ on slower ones. We knew generating the list at build time would be an easy win.
- Request waterfall: When loading the app, we had one request to verify if the user was logged in, and only then would run all router loaders in parallel. We knew we had some heuristics on the FE that could help us predict if the user is logged in. We only needed to ensure we could fail gracefully when our prediction is wrong.
- Rendering blocking: Fetching custom activities and custom fields were
blocking the rendering of other parts of the Lead page that were already
ready. These objects were unrelated and we just needed to use
Suspensefor these parts of the app instead of usingawaitin the loader.
Known Unknowns
- Modernizing transpiler libraries: We were on an old version of Babel,
browserslistand still oncorejsv2. Some things that modern browsers already support were still being polyfilled, and upgrading these libraries could speed up things a little. - Prefetching data on
loader: Although we upgraded our router, we were not using it in full capacity, and we were still fetching data inside components. Although moving everything to theloaderis a big effort, just pre-fetching the data was possible because we use Apollo GraphQL – which automatically dedupes the requests and saves the data to its cache. - Lazy load third party scripts: We use quite a few third parties: Sentry, Segment, AppCues, PartnerStack, Google Analytics 4, Google Tag Manager. Except for Sentry – which is used for catching bugs and should be initialized ASAP, all the others could be loaded after the app is no longer busy loading our own scripts and data.
- Tweak our async imports and
SplitChunksPluginalgorithm: When loading our app with your Developer tools open on the Network tab, you’d see that we were making more than 250 requests. This happened because we were very aggressive with the amount of async imports and usage oflazycomponents + very strict when telling how Webpack should calculate the max file size per generated chunk. When this was developed, those things were relevant, but years later it was time to revisit and check if we could tweak these to make sure we find a good balance between amount of files vs size of each file.
Unknown Unknowns
While working through the items, really paying attention to the network tab, and also using the profiler tab to figure out what’s taking too long to render / blocking other resources, all the work opened up for more ideas for exploration / investigation:
- Use
<link rel="preconnect"(most important) and<link rel="dns-prefetch"(less important) for domains that we know upfront we would be fetching assets from (e.g., our CDN, Sentry, Status Page). - Use
<link rel="preload"for stylesheets and scripts that are core to our app and that we know in advance we’ll be adding to the page. We’ve also benchmarked<link rel="modulepreload", but the former has better browser support, and performed slightly better than the latter anyway. - Use
<link rel="preload"for chunks specific to the page being loaded. - It's been standard practice for us to prefetch heavily-used JavaScript, but we moved to prefetching only after user interaction and when the browser is idle so they don't compete with any rendering.
- Some of our lists were rendering all items although only a few of them were visible upfront. This happened due to a component that is used for displaying a nice transition when the user expands or collapses the list. The component was changed to only load the entire list after the first time the user expands it.
- Bug fix: when loading the list of activities, the first page comes with 20
activities which is more than enough to fill any large monitor. Then if you
scroll down, when you’re approaching the end of the page, our
IntersectionObserverwill kick in and start fetching the next page. The problem was that ouruseIsElementNearViewporthook started observing the DOM too soon, and sometimes the event would kick in even before the list was fully rendered, making an intermittent over-fetch of 2 pages instead of only the first one. - When revamping our async imports, we were able to create a helper named
optimisticImportwhich calls React’slazyunder the hood, but also replaces it with the actual component as soon as possible, so hopefully by the time the component is used for the first time, it doesn’t need to suspend at all. - The Lead page renders hundreds of components, thousands of DOM nodes. In order
to improve the rendering performance, we created a new component:
LazyRender. It's used for rendering only the visible part of a component, and scheduling the rest withstartTransition. It can be used on Selects, Popovers, Modals, etc. This reduced the full render of the page from ~600ms on slower machines to ~200ms. Total block time was reduced by ~63% as well. - Last but not least, we did a lot of small changes to the Lead page itself:
- Parallelizing all promises on the page's
loadermaking sure we don’tawaitanything. - Memoizing all list item components.
- Prioritizing the most important piece of UI to render first (the list of
activities), and leveraging
startTransitionto schedule the less important ones. - Removing some Cumulative Layout Shift (CLS) with skeletons.
- Parallelizing all promises on the page's
Measuring improvements
When working on performance improvements, one thing always stands out: it’s hard to know if the work you’re doing is actually really making an impact.
Due to the nature of performance benchmarks, there are many things that can affect the numbers:
- Network conditions (DNS lookup, CDN that serves our assets, cloud where we host our app)
- Database / Backend load
- Virtual machine running the test
This project in particular was very challenging as there was no clear “big win”. Most of the changes would make things 2%, sometimes 3% better.
We've done a few things along the years to help with that:
- Automatically running snapshots with our automated benchmarking tool (Calibre) over time to catch a trend.
- Manually running multiple snapshots after a single change and comparing the median.
- Manually doing multiple refreshes on a side-by-side comparison (with a small Chrome extension I developed that runs the same code in two tabs – you can see a demo later in this post).
- Automatically running multiple snapshots on branch previews and comparing with production preview (more on that later in this post).
Results
After a few weeks and more than 50 PRs shipped, we were able to get the LCP down to 3.67s:
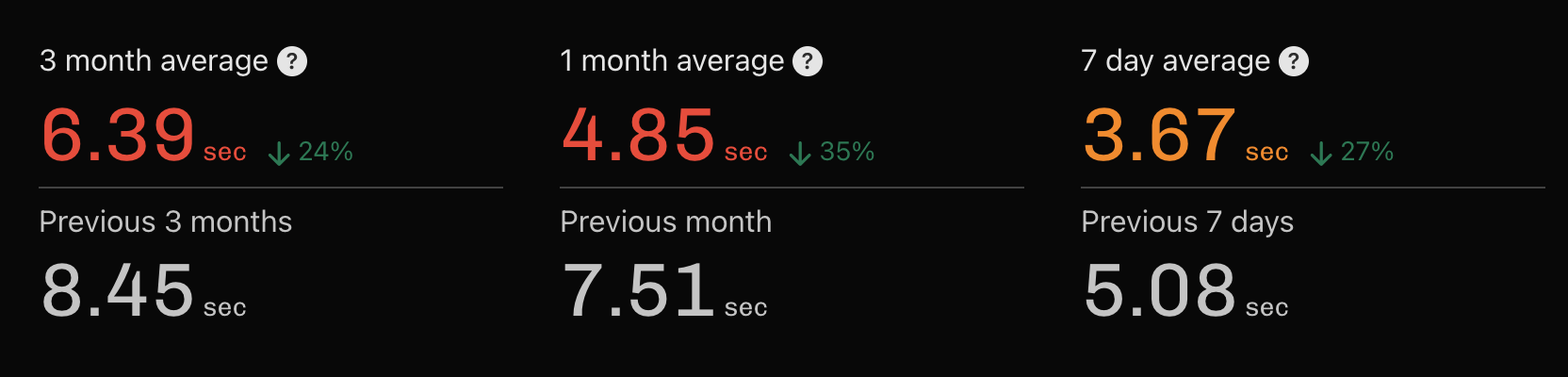
Week after week we saw improvements and now we’re more than 20% below our EOY goal.
Here is a before / after comparison using the browser extension mentioned above:
Avoiding regressions
Making sure the performance doesn’t worsen over time is as important as improving the performance itself. Although we had our tool running performance checks regularly, most of our team didn’t have access to the tool, and even those who did, wouldn’t check it consistently.
In order to improve that, we’re now running performance checks on every branch preview. We run the snapshot 5 times for each page being tracked and compare its median with the median of the production branch preview runs from the last 24h and add a comment like this to the PR:
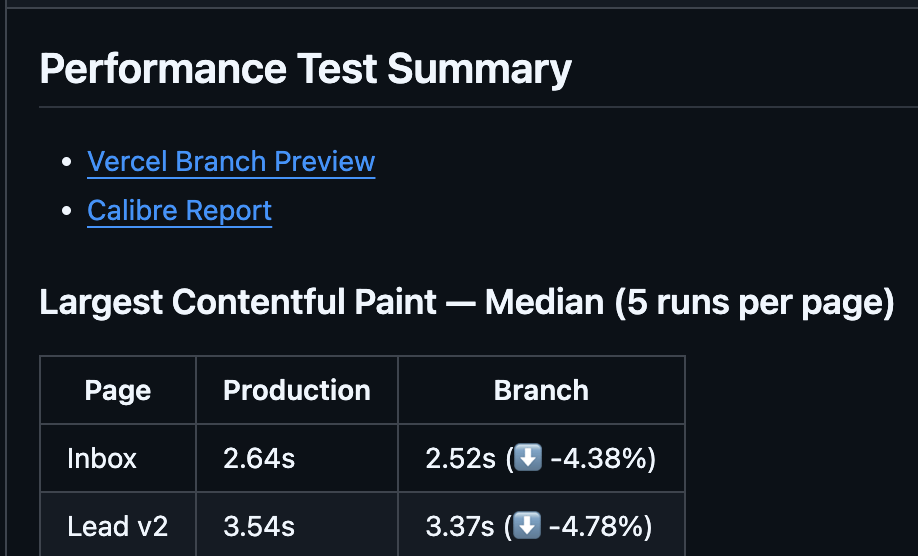
This gives us more confidence that our PRs are not introducing any performance regressions.
Future
As you can see, we’ve done a lot of work: from leveraging new browser APIs, tweaking our build process, revamping our async imports, to refining CPU utilization when rendering individual components, there is no free lunch when it comes to performance.
That said, performance is a never-ending matter. So beside making sure we keep things fast over time, we need to always be looking for new opportunities for improvements:
- Tree-shaking: right now our app only tree-shakes third parties.
Unfortunately we have some legacy code with side effects that prevents us from
tree-shaking our own code. This means that even if a chunk only needs, for
example, one function from
utils/date.ts, the chunk will contain all functions. In the end, we end up creating larger shared chunks which is fine, but could be better. - Smaller CSS chunks: in the past 4-5 years we created a very nice design system with many layout components that help us write almost no CSS when developing features. That said, we still have a lot of code that predates that, and they all use custom CSS, which makes our CSS bundle much larger than it should be.
- Smaller JS chunks (and faster script evaluation, parsing etc): we still have some legacy code that depends on bloated old libs (Backbone, with Backbone Forms, Backbone Relational, underscore, jQuery). Once we finally get rid of them, our JS chunks will be healthier.
- Moment.js full removal: earlier this year we migrated our entire codebase
from Moment.js to Day.js and also got rid of Moment.js Timezone lib – except
for one component: our date pickers rely on
react-dates(and although there is an issue from 2018, it’s not going anywhere). This means that our component now receives a Day.js instance and converts from/to Moment.js to consumereact-dates. We have plans to replacereact-dateswith another lib (that’s also smaller in footprint), and when this happens, we’ll get rid of Moment.js altogether. - Vite and React Router 7: As mentioned on a previous blog post, we plan on migrating from Webpack to Vite, and then upgrade React Router to v7. This will present an opportunity to explore Server-Side Rendering (SSR) that could prevent an essential waterfall that happens today: as with any single-page-app, the browser fetches a blank HTML page full of script tags which fetch the data and render the page.
OK, this post became a bit longer than I anticipated but I hope you enjoyed reading it! As always, feel free to reach out to me @vbuzinas on X for any questions and/or feedback. Thank you!