
Under the Hood: Developing Close's AI-Powered Call Assistant
Our internal teams have long benefited from meeting transcription tools, witnessing firsthand the efficiency gained from automatically logging transcriptions and notes for meetings. Recognizing the immense value this capability could bring to our users, we set out to integrate similar functionalities directly into Close.
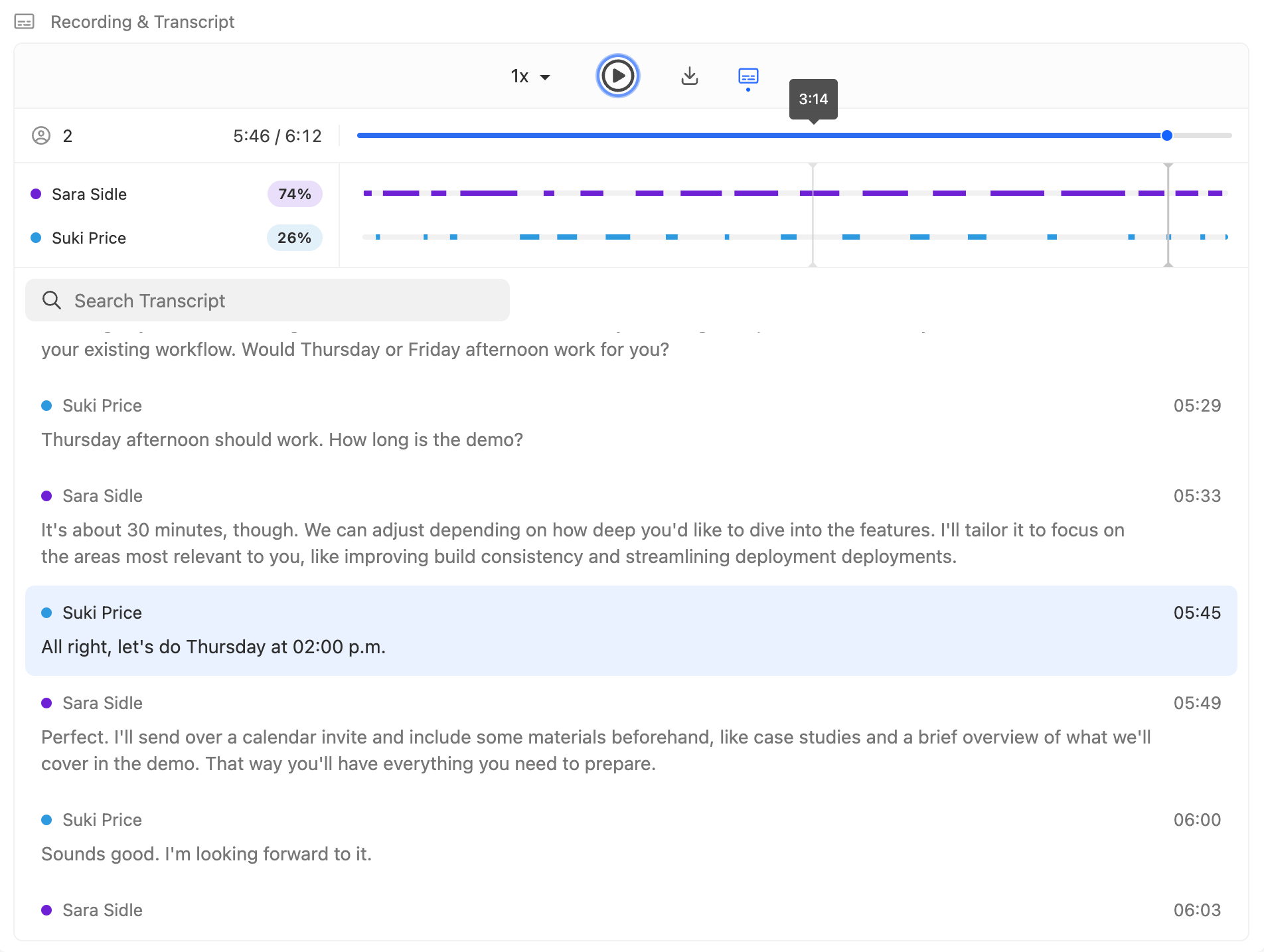
The Call Assistant provides transcriptions of calls made on our platform, offering immediate benefits to our users by delivering crucial context and insights into their interactions. Along with each transcription is a summary of the call, which allows sales reps to understand previous call activity in seconds without having to listen to the entirety of a call recording, providing a more efficient handoff. To make all the above possible, we teamed up with AssemblyAI, a leading provider known for their speech recognition and transcription services.
In this blog post, we will dive into the key learning points and major focuses we had while planning and building out the Call Assistant. We will explore the requirements and engineering insights, highlighting the approaches and challenges we encountered during development.
Glossary:
- Transcript: Record of all spoken words. Made up of utterances.
- Utterance: Complete unit of speech by a singular speaker. This can be a single word, a phrase, a sentence, or a longer stretch of speech.
- Speaker diarization: Process of identifying speakers in an audio recording.
Understanding the Requirements:
Before we began building the Call Assistant, we wanted to ensure that product, design, and engineering were all aligned on what our non-negotiable features were before we released to the general public.
We wanted to deliver a modern interface that feels intuitive but also one that provides actionable insights for teams that frequently review calls. With that in mind, the following were the most important criteria for launch:
- The transcription interface should be designed for ease of use, clearly presenting pertinent speaker and time information. It should effectively break down the call dialogue to display each spoken segment along with the corresponding speaker, referred to as an utterance. Additionally, the interface should allow users to interact with any utterance, enabling the audio player to start from the beginning of that specific segment.
- Speaker diarization: Accurately identify when each user spoke during a call and visually represent this on a timeline. Each user’s speech is displayed as a distinct, solid-colored horizontal bar, indicating the duration from when they started speaking to when they stopped. This visual timeline should be fully integrated with the audio player and transcript interface, allowing users to navigate seamlessly between the timeline and the corresponding audio and transcript segments.
- As real-time as possible: Real-time transcriptions are our ultimate goal, but given limitations, we had to optimize transcripts and summaries in a different way.
- Call summaries: Summaries should capture the main point of the call, dissecting it into key topics. Beyond highlighting crucial points, it should be divided into structured sections dedicated to each topic.
Enhancing Speaker Diarization with Dual-Channel Recordings
Breaking down recordings into distinct segments with correctly identified speakers, known as speaker diarization, is crucial for generating accurate transcriptions. Without precise transcriptions, the Call Assistant cannot provide insightful speaker talk time analysis, and resulting call summaries would be incorrect and unhelpful.
During project discovery, we observed significant inaccuracies in speaker identification. While AI tools can perform amazing tasks, they may still produce inaccurate results. Speaker diarization presents challenges in single-channel recordings due to potential audio cues, overlap, interference, and context dependency.
These inaccuracies prompted us to prioritize transitioning our recordings to dual-channel format to enhance speaker diarization accuracy. In dual-channel recordings, each channel represents a distinct speaker (although there could potentially be multiple speakers on one side of a recording).
Providing AssemblyAI’s Speech Recognition model with dual-channel recordings enables the model to differentiate speakers more accurately. This enhancement not only improves speaker identification but also ensures the capture of nuanced dialogues. With dual-channel recordings, we can effectively manage two sides of a call and accurately transcribe each speaker's contributions.
Refining Call Summaries with Prompt Engineering

Prompt engineering played a pivotal role in the development of our Call Assistant tool, enhancing the accuracy of call transcriptions and summaries. Prompts are inputs or instructions given to AI tools to guide their responses and outputs to meet specific goals. Developing our prompt was a game of iteration based on user feedback. We focused on crafting prompts that effectively capture the most important aspects of each call, ensuring that our summaries are both relevant and comprehensive. We kept the following in mind when developing our prompt for our call summaries:
- Clarity and context: Provide the AI tool with as much context as possible about the call, including information about the speakers, their organizations, and the type of call (sales, consult, discovery, etc.).
- Structure: Ensure that you are specific in providing the desired structured output to the prompt. For example, “Bullet points that summarize the topics discussed. A header for each topic discussed.”
- Specificity: Be specific in your instructions. Clearly state what information you want the AI tool to focus on and be explicit in what you want it to ignore. For example, “Summarize X and preserve all meaning without including any additional information that is not present”.
- Consider edge cases: Anticipate and address edge cases and exceptions in your prompt to ensure consistent and accurate outputs.
Prompt engineering is not merely about creating a set of instructions; it’s a dynamic process that evolves with user feedback and ongoing refinement. By emphasizing clarity, context, structure, specificity, and anticipating edge cases, we can develop prompts that effectively guide our AI tools to generate accurate and meaningful outputs.
Optimizing Performance: MP3 to WAV
Our ultimate goal is real-time transcriptions, but today that is not feasible. In the meantime we've focused on minimizing the turnaround time from the end of a call to displaying transcriptions and summaries in our user interface.
An important step in achieving quicker turnaround times for call transcriptions and summaries was transitioning from from requesting MP3 files from Twilio to requesting WAV files. We discovered that Twilio, by default, stores all recordings in WAV format. So, when we initially requested MP3 files, Twilio was transcoding the stored WAV files to MP3 format on the fly. This transcoding process was surprisingly slow, taking more time than simply downloading the larger, uncompressed WAV files.
Following this transition, we observed significant improvements in turnaround times. Larger audio recordings yielded even greater performance benefits. To provide context, for a 30-minute call, we reduced turnaround time by an average of 4 seconds. For a 60-minute call, the average reduction was approximately 9 seconds.
While real-time transcriptions remain our ultimate goal, the transition to using WAV files instead of MP3 files ensure that our users experience minimal delay between the end of their calls and the availability of transcriptions and summaries in the user interface.
Tackling Longer Transcriptions with Virtualization
At Close, calls can range anywhere from mere seconds to 4 hours. While the majority of our calls do not hit that 4 hour mark, we needed to ensure that we could gracefully handle the longer call transcriptions. During our initial discovery, we found that there were noticeable UI delays for the longer transcriptions. The UI delay left the transcription component blank momentarily while all of the utterances were rendered. This delay stemmed from rendering such a high number of utterances to the UI.
To address the UI delays with the longer transcriptions, we turned to virtualization. But what exactly is virtualization? Also known as windowing, virtualization is a technique that renders only the items visible within the user’s viewport. This method efficiently handles scrolling and renders only the necessary items, significantly boosting performance, especially with larger datasets.
While virtualization offers numerous benefits, we also considered its drawbacks. The downsides being that it breaks the browser's native search functionality, and users cannot copy the entire transcript. To address breaking the browser’s native search, we have two separate search functionalities: one that operates at the broader page level and another specifically for searching within a transcript. These two searching mechanisms ensure our users can still find relevant information efficiently. Additionally, we recently implemented a 'copy transcript' button to address the challenge of not being able to copy the entire transcript seamlessly.
We opted to use an existing library to handle the virtualization for the transcriptions. Ultimately, we chose React Virtuoso. While it is a heavier package compared to some other alternatives, we felt that it would benefit our application in multiple ways. React Virtuoso would be able to replace uses of an older virtualization library in our app, but also offers comprehensive functionality out of the box, like scrolling to specific items and handling variable height items effectively.
Once we integrated our transcription component with React Virtuoso, we saw no difference in the performance of the UI between the shorter transcriptions and longer ones. With virtualization, we are able to manage transcriptions of any length without concerns of compromising the user experience.
Seamless Sync: Transcript and Audio Player
Our goal was to create a seamless integration between the transcription and the audio player, ensuring a smooth experience for users. In order to make that happen, we wanted the transcript to always display the utterance that corresponds to the time on the audio player, display the current utterance in a way that distinguishes it from other utterances, and automatically scroll to the current utterance if necessary to always keep it in view. Clicking any point on the audio or speaker diarization timeline would then align the correct utterance with the audio player/speaker diarization timeline, while clicking on a single utterance would fast-forward or rewind the audio playback.
Most of these functionalities were straightforward to implement. However, we had to take a step back and find the quickest and most performant solution when synchronizing the audio player to the transcript as the recording played. Given that the number of utterances in a transcription can be quite high, looping through all utterances to find the current one can get quite expensive given the number of re-renders triggered by time updates of the audio player.
Instead of looping through all utterances to find the current one on every time update, we took a bit of a different approach. Since utterances are arranged chronologically and match the audio player's playback order, we used the end time data of each utterance to determine if it is an current utterance or not. On every time update, we compare the current time on the audio player with the end time of the current utterance. If the audio time exceeds the end time of the current utterance, we move to the next utterance. This method significantly improved the performance of the syncing, and provided the seamless integrating we aimed for between our transcript and audio player.
Accessibility in Speaker Diarization
Speaker diarization plays a crucial role in the Call Assistant by breaking down the talk time by speaker, which is important for understanding conversational dynamics and analyzing interactions. In creating speaker diarization visualizations, accessibility was a key consideration.
We’ve used special attributes and semantic structure to ensure that the
visualizations are clear
(W3C Graphics Module recommendations).
For instance, we designated the role of the SVG as
role="graphics-document document", which helps assistive technologies
understand its purpose. Each part of the visualization, such as the
solid-colored horizontal bars representing utterances, includes descriptive
labels like start and end times, making the content easily interpretable by
screen readers. The SVG’s content is organized semantically using groups with
the role of role="graphics-object group" to signify distinct graphical objects
related to speaking time.
To ensure the speaker diarization timeline was both interactive and accessible,
we placed an input element with type="range" at the top of the diarization
section. This allows users to click anywhere within the timeline to seek the
audio track to that precise location. Since the range input matches the width of
the audio player scrub bar, clicking within the diarization timeline moves the
audio to the exact corresponding point.
These accessibility enhancements are crucial in ensuring that all users can engage with and understand the speaker diarization visualizations effectively, regardless of their method of accessing the content.
Conclusion
The development of the Call Assistant represents a significant stride in enhancing our user experience. By integrating transcriptions, speaker diarization, and call summaries, we've empowered our users with valuable insights and improved efficiency in their sales processes.
As we look to the future, we are excited about the potential for AI-driven improvements and new features to Close. We are committed to staying ahead of AI innovation and continuing to equip our users with features that ultimately contribute to their success in meaningful ways.