
Taming Python GC for Faster Web Requests
“What do you mean, ‘memory management’?” - every python dev, ever
TL;DR
Python garbage collection:
- is not free
- can be easily measured
- can be very easily improved
- may observably impact web traffic workloads (our p95 latency improved by 80-100ms)
To optimize performance, place this code right after the application initialization:
# initialize + freeze gc before starting the server
gc.collect(2)
gc.freeze()
# Start the GC sequence every 50k not 700 allocations.
_, gen1, gen2 = gc.get_threshold()
gc.set_threshold(50_000, gen1, gen2)And even better, instrument the garbage collector with OpenTelemetry.
How did we get here?
Last year I spent a little over a month where my entire goal was just "make the app faster." As a backend-focused engineer, I of course collaborated with our frontend team and found some low hanging fruit - request waterfalls that could be avoided with an extra field or two, a few N+1's, and some opportunistic improvements to our dataloader patterns. BUT our frontend team observed one high-priority issue that did not fall into any of these buckets.
Sometimes, but just sometimes, requests would randomly take hundreds of milliseconds longer to complete. The issue was most noticeable on endpoints that delayed page loading (e.g. search results), but as I started looking into it more whatever caused it, it seemed to be equal opportunity - to some degree it impacted all endpoints. Huh.
Reproducing the Behavior
Our web processes have used gevent for a long time for concurrent IO. At
first, I thought that we must be doing some sort of CPU-bound processing (which
would block gevent's greenlet switching, and could stall other concurrent
requests). Either that, or maybe it had something to do with gevent's unholy
monkey-patching setup, which hijacks everything from socket IO to native locking
and threading and may introduce weird or buggy behavior (especially when calling
native C code).
Unfortunately, gevent's approach to concurrent IO makes it impossible to use
the
built-in tooling
to debug pauses / slow callbacks. But even after porting a branch to purely
asyncio, it turned out that we were still seeing this problem. The saving
grace was that at some point we figured out how to reproduce the behavior
locally - just spam refreshing any search request locally was enough to trigger
it.
So now with the ability to reproduce, and reproducing from a local asyncio-based branch we had full access to all the built-in asyncio debug tooling to work with.
... But ever single time we hit this issue, the debug tooling reported a different and seemingly totally random spot that had paused. Huh.
What can interrupt with CPU-bound work at any time?
As we pondered this, at some point years of hearing and not truly believing "stop-the-world garbage collection can happen at any time" came rushing back. Surely though python garbage collection wasn't interrupting for 150-200ms every dozen-ish requests, right? ... RIGHT?
There at least were now a few clear steps we could take to confirm:
- CPython has some nice documentation on how the garbage collector works, which we read up on.
- CPython has some built-in garbage collection inspection
(
gc.callbacks+gc.get_objects()) and debugging (gc.DEBUG_STATS) we can easily enable locally.
A brief foray into python garbage collection
In short, python tries to reclaim most memory by counting references to objects. But this strategy doesn't really work when you have circular references - that is, if you do something like this:
a = A()
b = B(a=a)
a.b = bNow even if there's no local scope that references a or b, they still
reference each other and will never be collected by reference counting. That's
where the garbage collector comes in to save the day.
Each object is tracked by the garbage collector, and every so often the garbage collector will look through every object we have in memory and tries to find unreachable objects - objects with non-zero reference counts that are no longer accessible from the program and can be otherwise cleaned up.
As a performance improvement, it does this in generations. It tracks three generations, and each time an object survives garbage collection it'll push it into the next generation. Then every few times it collects younger generations, it'll cascade up to collecting older generations too.
And now back to our hero...
From debugging, we noticed that the garbage collector had a lot of data being
tracked in generation 2. This actually made a lot of sense. Our application is
relatively monolithic, and there's a lot of global setup that happens when the
app starts up and stays in memory for the entirety of the web worker's lifetime.
So every time the garbage collector tried to collect generation 2, it was
scanning a few hundred megabytes of objects that we already knew were not
collectible. From that comes our first obvious improvement:
gc.collect(2)
gc.freeze()By putting this snippet just after app initialization we're manually triggering
garbage collection, then with gc.freeze() telling the garbage collector to
completely ignore any object that's still being tracked. This takes our large
overhead and ensures the garbage collector doesn't have to scan it every time it
runs garbage collection on objects tracked in generation 2.
We deployed this change and it seemed to help! Though after looking at garbage collection stats locally for a while, I got an itch to track this stuff in production. So we did!
Garbage Collector Instrumentation
We use OpenTelemetry metrics for custom observables in our application code. Since we can install hooks to be called after garbage collection, all we had to do to get meaningful metrics out of production was wire these hooks up to some meters.
The full code snippet is available in a
github gist,
but the main thing that was interesting to track is the overall collection
times. The gc.callback payload tells us when collection starts/stops, and what
generation the collection ran on. So we can keep track of how long each
generation takes to collect and report on it.
Even after deploying the above gc.freeze() optimization, we got some
interesting results that suggested some further tuning was in order.
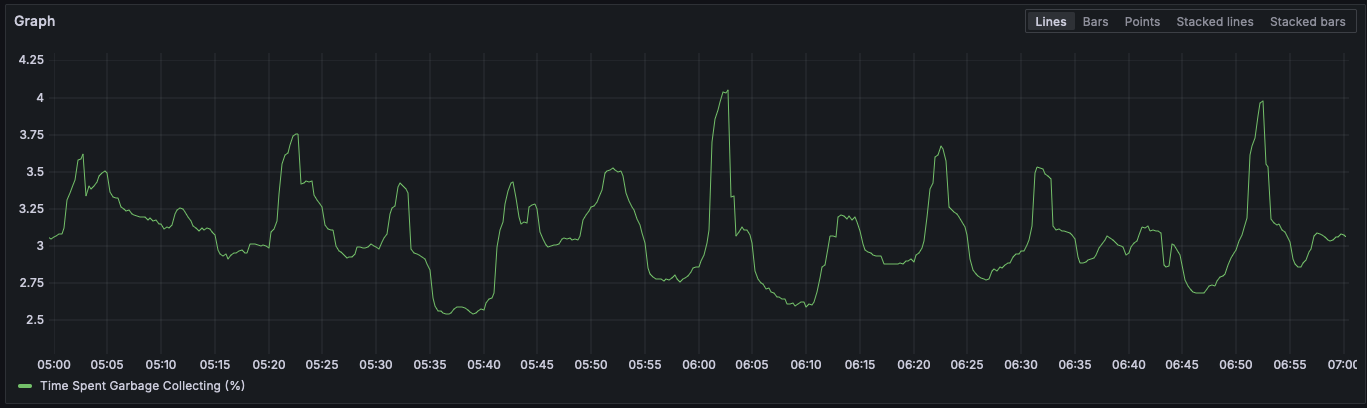
These graphs show about 3% of our runtime is spent in CPU-bound garbage
collection routines. And again that's after our gc.freeze() change.
3% may not seem like a lot, but our web worker deployments run on an autoscaler
that targets 35% CPU utilization per pod (which gives each some nice bursty
overhead). If we're spending 3% of our CPU utilization just doing garbage
collection, that means 3%/35% = ~8.5% of our allocated web resources are
still being spent just doing busywork. That's crazy!
Final Tuning
What other knobs does CPython give us to tune its garbage collector? The only
obviously tweak-able settings I saw documented were garbage collection
thresholds, set with
gc.set_threshold.
From the docs:
In order to decide when to run, the collector keeps track of the number object allocations and deallocations since the last collection. When the number of allocations minus the number of deallocations exceeds threshold0, collection starts.
With set_threshold, we should be able to give the process a little bit more
breathing room to deallocate via ref counting before triggering a more-expensive
garbage collection routine.
Right after our gc.freeze() call, we bumped the thresholds. threshold0
defaults to 700, which we bumped up to 50_000. This had a major impact on
our garbage collection metrics:
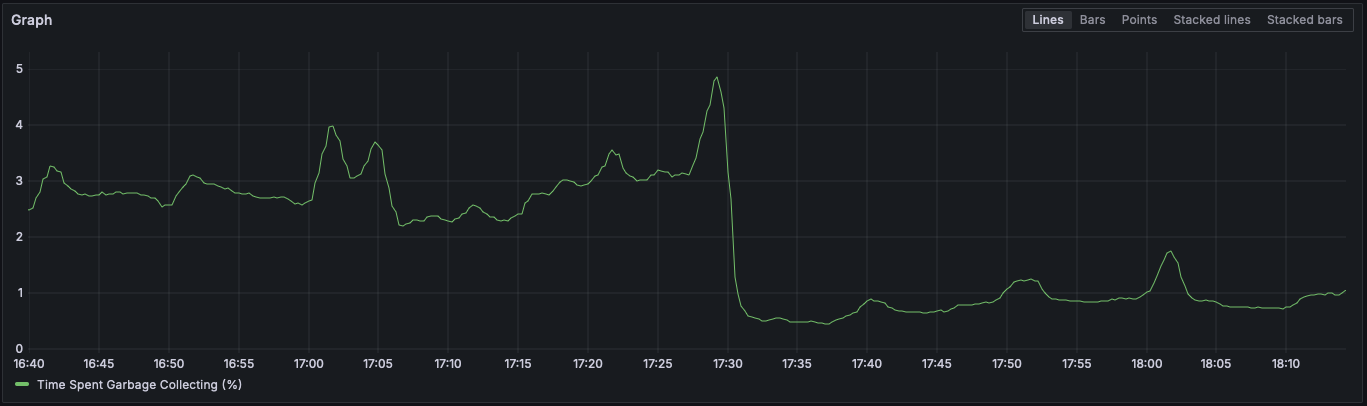
Our total garbage collection utilization fell off of a cliff, dropping from
~3% -> ~.5% of our total runtime. There were way fewer garbage collection
runs, since objects had a much better chance of being collected via
ref-counting. Each GC routine was actually collecting more of the objects it
examined each run, which is exactly what the GC is meant to be doing and means
it wasn't just wasting cpu cycles with busy work.
At this point we stopped seeing random pauses in our requests / traces. And we actually saw a measurable improvement in our overall p95 latencies, not just the specific requests we were trying to optimize:
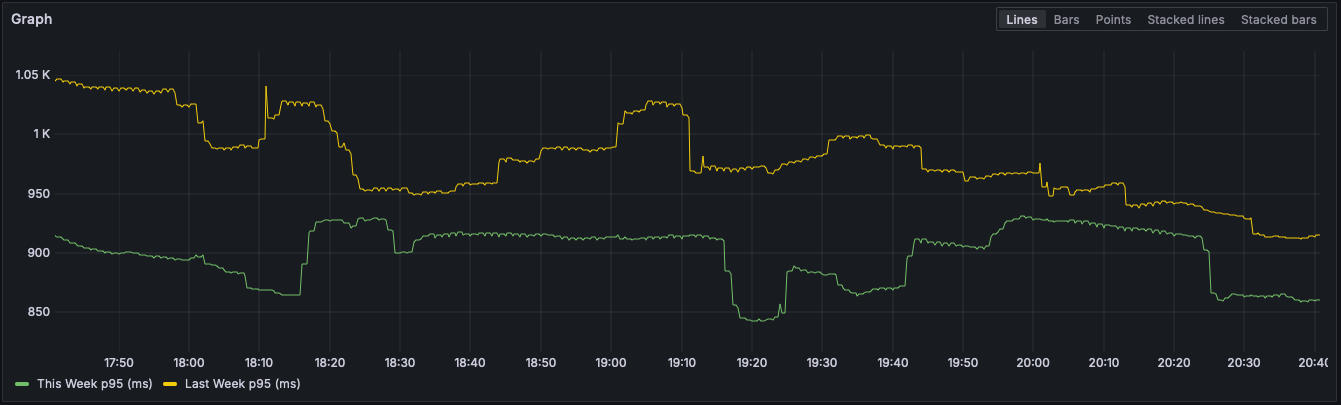
Nice