
How We Improved Reliability Of Our WebSocket Connections
We have recently squashed two long-standing calling bugs in Close with a single fix: Making our WebSocket connections bidirectionally robust. The final solution turned out to be quite simple, but getting there required understanding browser limitations, playing with our networking hardware, refreshing our knowledge of the Internet's foundational RFCs, and digging into several layers of logging. Let's start at the beginning though…
The Problem
Our customers love Close for many reasons, but one of the top ones is our built-in calling. However, over the last few months we'd sporadically receive concerning bug reports about this feature:
- Sometimes, when a Close user called a contact, the far end would pick up, but our UI still looked as if the call was ringing.
- Other times, a contact would call a Close user, but the ringtone would keep playing even after the user answered the call.
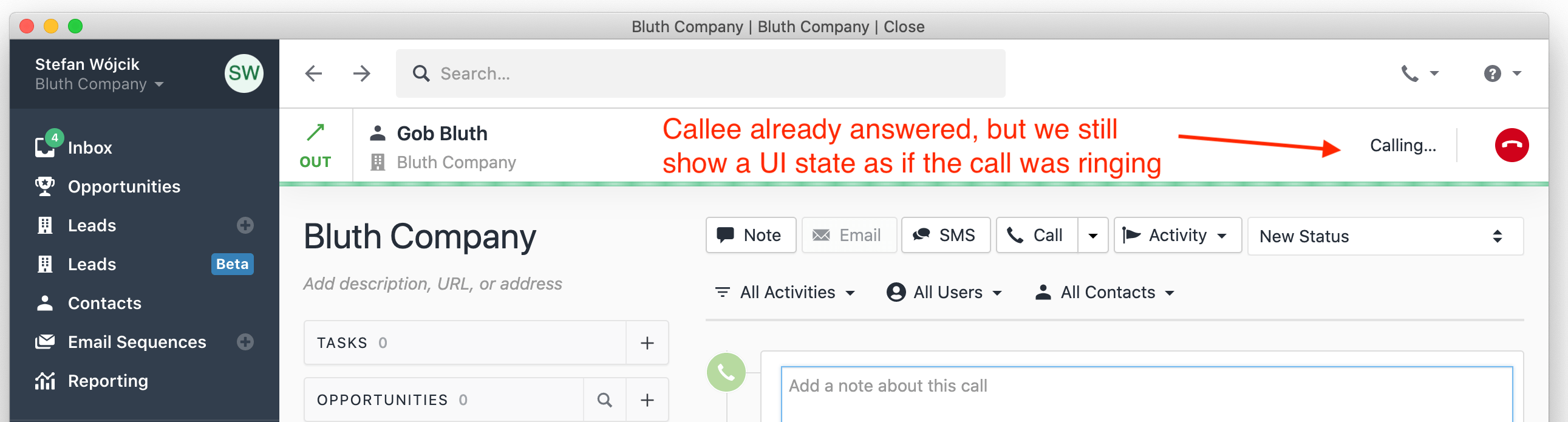
We couldn't reproduce either of these bugs and thus we had two options to choose from:
- The (sadly all too) common approach to rarely occurring bugs & edge cases: Pretend like the problem doesn't exist. Blame it on faulty networking, solar flares, etc.
- The responsible approach: Iteratively work your way through the problem, identifying what you don't know yet, and coming up with ways to answer your questions through logging, monitoring, additional tests, code refactors, research, etc.
We chose the latter.
Pulling The Thread
After a few rounds of logging improvements, we could walk through each step of the "call answered" event's journey and see where it veers off course. We saw that:
- When the callee answers the problematic call, Twilio (our telephony provider) recognizes this fact and sends a webhook about it to our backend servers.
- Our backend receives the Twilio webhook and processes it successfully. This includes publishing a "this call is now in progress" event to SocketShark (our open-source tool for managing WebSocket connections, based on Redis and Python/asyncio).
- SocketShark receives the Redis event and attempts to deliver it via a WebSocket to the relevant user. However, in case of the problematic calls, this turned out to be a no-op because the target user didn't have an active WebSocket connection.
This came as a surprise. Our system is set up in a way where you should always have an active WebSocket connection. We ensure this is the case in two ways:
- As recommended by RFC 6455
(which defines the WebSocket protocol), our backend sends periodic
PingControl Frames to each connected client. If it doesn't receive a matchingPongframe ("matching" means that it contains the same random 4 bytes of "application data") within a reasonable time, it closes the connection. - Our UI uses the
reconnecting-websocketlibrary and attempts to establish a new connection quite aggressively as soon as it determines that the previous connection was closed.
What were we missing then?
A Healthy Dose Of Self-Doubt
When it comes to debugging unexpected behavior, it's often good to start with challenging your own assumptions. It's not enough to read a comment or glance at a piece of code. You need to prove that what you think your code does is truly what happens.
That was our next step. We fired up the Close app, waited for our WebSocket to
connect, and verified if the Ping and Pong control frames are sent back and
forth. There's an important gotcha here though: In many browsers (e.g.
Chromium-based browsers like MS Edge, Electron, and, well, Chrome), you can't
see the Control Frames in the Network Monitor at all. Fortunately, Firefox has
a way to make them visible:
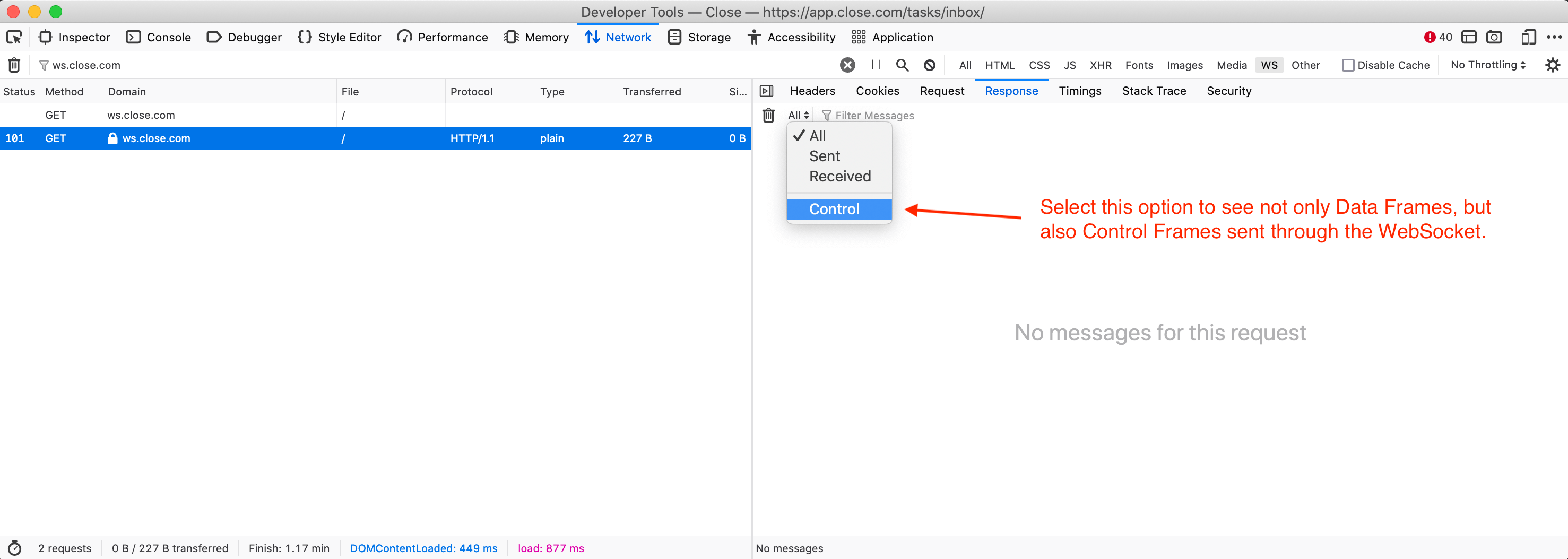
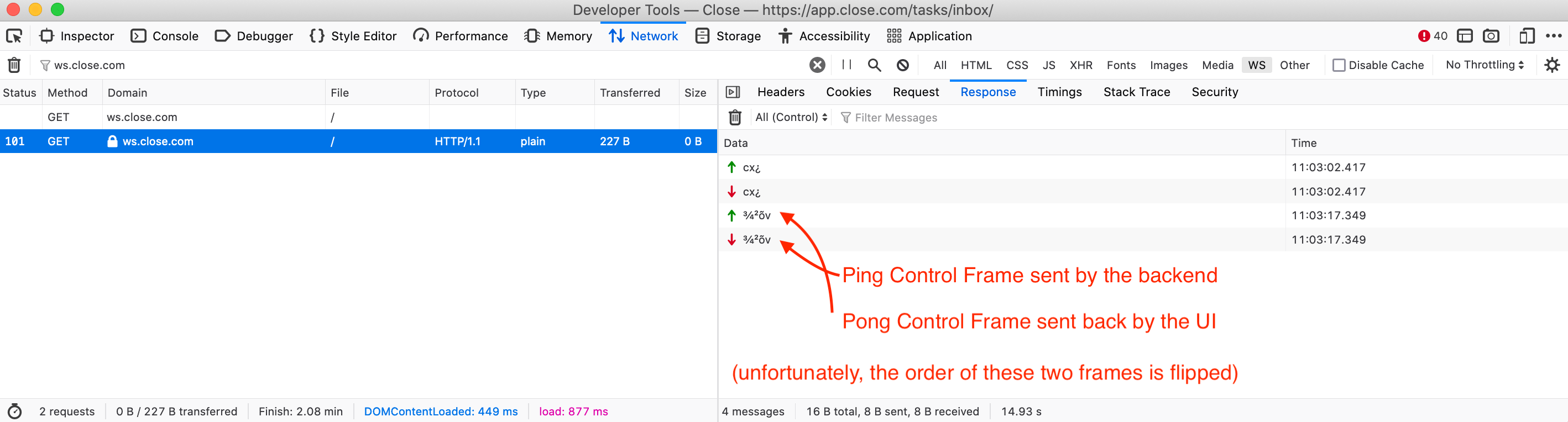
Alright, we've confirmed our first assumption – pings and pongs are flowing
nicely. Time to move on to the second assumption – is the
reconnecting-websocket working as advertised?
Breaking A WebSocket Connection
Our first attempt at permanently breaking the WebSocket connection was quite naive. We simply turned the Wi-Fi off and on again. That worked fine: The UI quickly recognized that the WebSocket connection got severed and reestablished it as soon as we got back online.
The second attempt involved playing with the Network Monitor built into the browser and its throttling options. Sadly, it turns out that both Firefox and Chrome only support throttling for HTTP connections and not for WebSockets. Moving on…
The third attempt was a bit more complicated:
- We looked up the current IPs of our Load Balancer using
nslookup. - Then, we used
/etc/hoststo pin one of those IPs toapp.close.com(the domain for our application's HTTP requests) and another IP tows.close.com(the domain for our WebSocket connections). - We loaded the Close app and waited for the WebSocket to connect.
- Then, we re-routed outbound TCP packets destined for the WebSocket-pinned IP
to a bogus local IP, so that they'd never reach our production servers:
sudo route -n add -net PINNED_WEBSOCKET_IP_ADDRESS BOGUS_LOCAL_ADDRESS - We waited for SocketShark's pings to time out and close the connection, since they no longer received pongs from our client.
- We removed the bogus entry from the routing table and observed what would happen in the UI.
(Un)fortunately, this also worked fine. As soon as the server closed the connection, the UI would try to reconnect repeatedly and – once we removed the bogus routing table entry – it would succeed. This, again, didn't explain how our users could have no active WebSocket connection for minutes or even hours.
This last attempt failed at reproducing the problem, but it informed our next steps. This is another important lesson in debugging tricky problems – you sometimes have to try unlikely scenarios, partly to rule them out, but also to inspire your next steps.
The fact that the UI immediately recognized the WebSocket connection as closed showed us that either a) the browser somehow realized it on its own, or b) the server-sent TCP packet containing the FIN flag (responsible for communicating the closure of the connection) was successfully received by the client (as described in RFC 6455, WebSockets use TCP for the underlying connection). Could we break the connection in a way where the server-sent TCP FIN packet never made it to the client, and the browser was believing the connection was still up?
Replicating this scenario turned out to be quite simple, once we set our mind on it:
- We opened the Close app and waited for the WebSocket to connect.
- We unplugged the Ethernet cable from the router (the one connecting the router to the Internet at large, not the one connecting the router to the computer [0]) and waited for SocketShark's pings to time out and close the connection. This time, the TCP FIN packet would not make it to the UI client.
- We plugged the Ethernet cable back in and waited for the Internet connection to come back… And there it was! The UI never recognized that its WebSocket connection was broken and never attempted to reconnect.
The Fix
The elation from finding reliable reproduction steps didn't last long. We still needed to figure out how to implement a correct fix. First, we did a recap of everything we knew:
- Our WebSocket reconnects as soon as it recognizes that its previous connection is closed.
- There is a networking failure scenario in which the UI side of our WebSocket doesn't recognize that its connection is closed.
- RFC 6455 defines the
WebSocket protocol, which supports two different types of frames:
Control Frames
(
Ping,Pong, andClose) and Data Frames (frames that carry your actual data). It also suggests thatPingcontrol frames "may serve either as a keepalive or as a means to verify that the remote endpoint is still responsive." (emphasis ours). - The backend side of the connection already sends
Pings and receives client-sentPongs to determine whether it's still connected to the UI.
This is when it hit us: Our UI needs the equivalent ping/pong mechanism as the backend to ensure connectivity on its side of the connection.
Unfortunately, browsers do not expose an API for sending Ping control frames
to the server nor acting on received Pong frames.
The request to expose such APIs has been rejected by the W3C years ago.
We were thus forced to implement this mechanism ourselves, using regular data
frames. This is
exactly what we did and it
worked like a charm! We haven't received a single report of the aforementioned
bugs since we've shipped it.
Conclusions
There are a few lessons that we're going to take away from this bugfix:
- Always make sure that you periodically poke both sides of any long-lived TCP connection.
- Not every connection failure is easy to simulate with software. Sometimes it makes sense to play with the good old hardware, power things down, unplug some cables, etc.
- When in doubt and feeling stuck, add more logging. Pull a thread till you find where it snaps.
- Don't outright dismiss the complex, unlikely scenarios. Certainly, go through the likelier steps first, but recognize that there's value in eventually pursuing the long shots. Worst case, you'll have one extra scenario that you've ruled out. Best case, it'll inspire your next steps.
[0] You might be wondering: Why does it matter which cable exactly we disconnect
from the router? Also, why didn't turning off the Wi-Fi (or unplugging the
router from the computer in case of a wired connection) reproduce the issue? The
thing is, the browser handles the "I'm not connected to anything" scenario (what
happens when you turn off Wi-Fi or unplug the Ethernet cable from your computer)
differently from the "I seem connected to the Internet, but my packets are
falling off a cliff" scenario (what finally reproduced the issue). If your
computer recognizes that its network connection has changed (i.e. what happens
when you turn Wi-Fi off/unplug the laptop), it will trigger a "network change"
event, which in turn will make the browser send a test Ping control frame over
all of its active WebSockets. If the corresponding Pong isn't received within
a reasonable timeout (Firefox uses 10 seconds currently), then the browser
assumes that the connection is severed and closes it on its side. The
reconnecting-websocket library takes care of the rest.